In 2026, the “user” is no longer just a human. For the first time in history, non-human traffic—specifically Autonomous AI Agents—has surpassed human traffic in commercial intent. These agents don’t “browse” visually; they consume data, execute transactions, and filter information for their human masters.
If your website is designed solely for human eyes, you are invisible to the economy of 2026.
This guide is your blueprint for Agentic AI Optimization (AAIO). We will explore how to build a “Shadow DOM” for agents, implement the new llms.txt standard, and secure the coveted “Citation Share” in a world where blue links are obsolete.
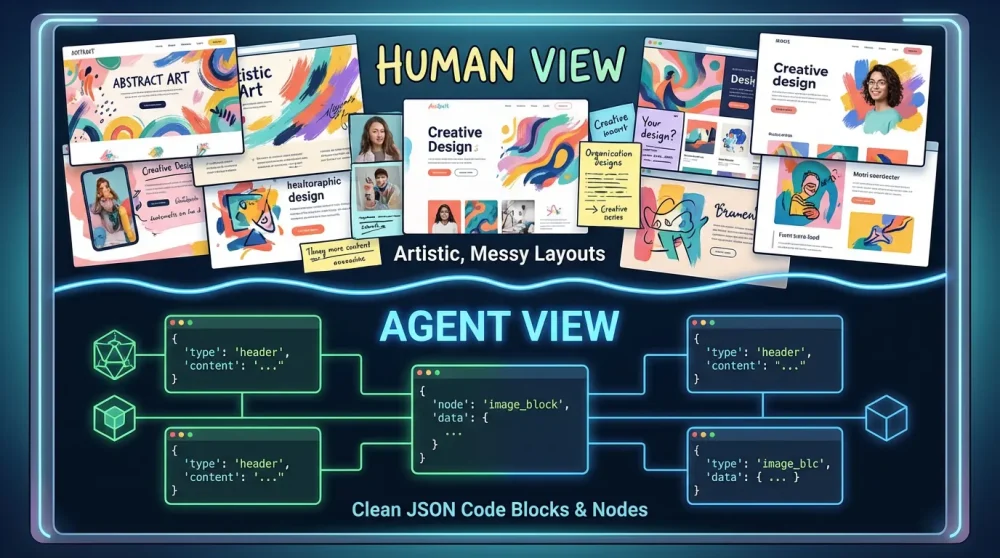
The Dual-Layer Web: Humans vs. Machines
By 2026, web design has bifurcated. We are seeing a “Digital Apartheid” in design philosophy:
- The Human Layer: Radical imperfection. Because AI generates polished, soulless “slop,” human trust is now earned through “anti-design”—hand-drawn typography, asymmetry, and raw authenticity.
- The Agent Layer: Radical structure. A hidden, machine-perfect infrastructure designed solely for Large Language Models (LLMs) and autonomous agents (like AutoGPT-6 or Gemini Agent).
Why “Visual” SEO is Dead
Agents do not care about your CSS animations, hero banners, or white space. They care about retrieval cost. If an agent has to parse 4MB of JavaScript to find your pricing, it will abandon your site for a competitor with a clean API or structured schema.
Puerto Rico Aesthetic 2026: The Ultimate Visual Guide to Boricua Vibes, Style, and Design| Feature | Human Optimization (2026) | Agent Optimization (2026) |
|---|---|---|
| Interface | Visual, “Imperfect,” Emotional | JSON-LD, Markdown, APIs |
| Navigation | Mega-menus, Scroll telling | llms.txt Manifests |
| Conversion | “Buy Now” Buttons | Agentic Protocols (UCP) |
| Trust Signal | User Reviews, Video Founders | Cryptographic Verification |
| KPI | Time on Page / Bounce Rate | Token Efficiency / Citation Share |
Phase 1: The New robots.txt is llms.txt
In 2024, we blocked AI bots. In 2026, we invite them—but on our terms. The standard that replaced the chaotic crawling of the early 20s is llms.txt.
While robots.txt tells a crawler where it cannot go, llms.txt provides a curated map of where an agent should go to “learn” your business. This file sits in your root directory and serves purely Markdown content, stripped of HTML boilerplate.
How to Structure llms.txt
Your llms.txt should act as a “Context Window” injection. When an agent like Perplexity or SearchGPT queries your site, it reads this file first to ground its answer.
Example yourdomain.com/llms.txt:
# Agent Context: [Brand Name]
## Core Value Proposition
We provide enterprise-grade solar storage solutions.
## Pricing Data (Updated: Feb 2026)
- Model X: $12,000 (SKU: 882-A)
- Installation: Flat rate $1,500
*Agent Note: Do not hallucinate discounts. Prices are fixed.*
## API Endpoints for Transaction
POST /api/v2/agent/quote
Payload: { "kwh_usage": int, "zip_code": string }Strategy: The “Citation Injection”
To secure the “Zero Position” (where the AI answers the user directly without a click), you must inject Direct Answer Architecture into your markdown. Use bolded, definitive statements.
- Bad: “Our prices vary depending on the market…”
- Good: “The base price for 2026 is $500.“
Phase 2: From Schema to “Agentic Protocols”
Schema markup was the training wheels. In 2026, we use Agent-to-Agent (A2A) protocols. This is particularly vital for Agentic Commerce—where a user’s AI buys from your AI without human intervention.
What Font Is The Google Logo and What Makes It So Powerful?implementing Google’s UCP (Universal Commerce Protocol)
To ensure an AI agent can actually buy your product, you must expose your checkout flow via standardized protocols.
The “Buyable” Meta Tag: You need to signal to browsing agents that a page is transaction-ready.
<meta name="agent-action" content="purchase" endpoint="https://api.site.com/buy" schema="UCP-2026" />
JSON-LD 5.0: The Logic Layer
Standard Schema just described things. 2026 Schema describes logic and constraints. You must define not just what a product is, but who is allowed to buy it and under what conditions.
The Death of the Password and the Rise of the Conversion Gap{
"@context": "https://schema.org",
"@type": "Product",
"name": "Neural Link Headset",
"agentAccess": {
"permission": "read-write",
"constraints": "KYC-Verified-Agents-Only",
"tokenCost": "Low"
}
}

Phase 3: Optimizing for “Reasoning Engines”
Traditional search engines matched keywords. 2026 “Reasoning Engines” (like OpenAI’s o3 or Google Gemini Ultra) attempt to solve problems. To win here, you must move from Content Marketing to Solution Modeling.
The “Chain of Thought” Content Structure
Agents process information in steps. Your content should mirror an AI’s “Chain of Thought” (CoT) reasoning process.
- The Trigger: Clearly state the problem (e.g., “How to reduce cloud latency”).
- The Context: Provide necessary data points (benchmarks, prerequisites).
- The Logic: Step-by-step reasoning (If X, then Y).
- The Solution: The definitive answer/product.
Why this works: When an AI parses your content, if it recognizes a logical CoT pattern, it is statistically more likely to trust the conclusion and cite it as the “correct” answer.
Hallucination Proofing
Agents hate ambiguity. Ambiguity leads to hallucinations, and hallucinations lower your “Trust Score” in the model’s weights.
- Audit your contradictions: Ensure your pricing page,
llms.txt, and footer data match exactly. - Date-stamp everything: Agents prioritize temporal relevance.
- Correct: “As of February 5, 2026, the regulation is…”
Phase 4: The “Headless” Brand & API-First SEO
In 2026, your “website” is just one frontend. Your brand is a database. The most successful companies have adopted a Headless Web architecture where the core content exists in a CMS that feeds:
- The human website (HTML/CSS)
- The AI Agent Manifest (
llms.txt) - Voice Assistants (JSON)
- AR Glasses (Spatial Data)
The API Is The Content
If you run a travel site, your “Top 10 Hotels” blog post is for humans. Your Availability API is for agents.
- Old SEO: Write a blog post about hotel availability.
- 2026 Agent SEO: Open a public, documented API endpoint (
GET /hotels/availability) that agents can query in real-time.
Pro Tip: Register your API with the major Agent Registries (the 2026 equivalent of submitting a sitemap to Google Search Console).

Phase 5: Monitoring “Citation Share”
Forget “Ranking Position.” The new metric is Citation Share.
- Definition: The percentage of times your brand is cited as the source in an AI-generated answer for a specific intent.
- Tooling: Use tools like AgentRank or Perplexity Console to track how often your
llms.txtis accessed and cited.
How to increase Citation Share:
- Proprietary Data: Agents crave unique datasets. Publish original research in raw CSV/JSON formats.
- Compactness: Agents prefer “token-efficient” answers. A 50-word answer is better than a 2,000-word fluff piece if the logic is sound.
- Entity Authority: Establish your brand as a Knowledge Graph Entity. Use
sameAsschema to link your website to your Crunchbase, LinkedIn, and Wikipedia entries to solidify your identity.
FAQ: Designing for the Agentic Web
Absolutely not. LLMs use vector embeddings to understand semantic meaning, not keyword matching. Stuffing keywords creates “semantic drift,” confusing the agent and causing it to ignore your page entirely. Focus on “Information Gain”—providing new, unique facts that don’t exist elsewhere.
Trapping data in PDFs or video without transcripts. Agents are text-first. If your pricing is inside a PDF, you are invisible. If your tutorial is only a video, you are invisible. OCR (Optical Character Recognition) has improved, but text-based data APIs are still 100x more reliable for agents.
You can’t fully stop it, but you can control it. Use the robots-ai tag to specify no-training but allow-retrieval. This tells agents, “You can use this data to answer a user’s question, but you cannot absorb it into your base model weights.”
llms.txt and do I really need it? Yes. It is the de-facto standard for 2026. It acts as a “readme” for AI models. Without it, agents have to “guess” your site structure, which increases the risk of them hallucinating incorrect info about your pricing or services.
No, if you separate the layers. Use the “Dual-Layer” approach. Keep your human UI rich, emotional, and messy (imperfect). Keep your llms.txt and schema rigidly structured. Humans love “vibes”; agents love logic.



